S1E2 衡量 API 设计质量的指标 — TTFC/TTFHW


本期是 API Letter 的第二期,天津下起了小雨,一场秋雨一场寒,我在雨中为你撰写这封 Newsletter。
任何一个开放平台类产品,要解决的问题都是如何在现有的平台能力之上,开放一些能力给到第三方开发者,帮助第三方开发者开发应用,拓展体验,如果我们可以降低开发者在完成开放能力接入所需的时间,我们就可以让开发者有更多的时间去构建属于自己的业务逻辑,拓展平台之上的应用生态和开发者体验。
API 的设计质量、文档质量和错误处理信息的质量可以非常明显的影响到 API 的使用体验。但这些体验却很难通过我们在软件工程领域所使用的各种性能指标来衡量。我们可以通过一些专业的、对于 API 有判断能力的人来完成对于 API 质量的评估和优化的引导,但这件事并不利于持续发展和长期迭代。我们需要一个靠谱的指标,来引导我们持续性的、规模化的进行 API 本身的优化和迭代。

在这个问题上,Slack 给出了自己的答案 —— Time to First Hello World(TTFHW), API 服务提供商 readme.com 则提出了一个类似的概念 Time to First Call(TTFC)。
TTFC/TTFHW 为什么是一个好的指标?
在 TTFC 之前,我相信你或多或少都试过对自己的 API 进行统计和分析。你可能会基于技术工程指标来判断 API 的好与坏;进一步则会通过一些反馈的能力来完成(比如划词反馈、点赞点踩反馈)数据的收集和进一步的分析,你可能会将这些数据进行加权分析,从而得出一个质量评分,用于判断一个 API 的好与坏。
表面上来看,他可以帮助你发现你的 API 当中的不好的点,你可以基于开发者的反馈来快速对 API 当中的一些问题来进行修复,从而提升开发者的开发体验。但这个指标的一个缺点是:它是一个负向反馈的指标。作为 API 的提供者,你拿到这些反馈的时候,它可能已经早已影响了你的大多数开发者,甚至早已令你的开发者十分不快而你却从不知道。不仅如此,如果你的开发者们并不喜欢反馈,你的 API 的问题可能永远都不会暴露出来。
TTFC/TTFHW 如其名所述,记录的是一个开发者第一次调用所需要时长,你可以根据你自己的需要,来设定开发者行为的起点。而终点,则是开发者成功发起一次调用。
相比于需要开发者主动反馈所进行的数据收集,TTFC/TTFHW 的指标不需要开发者做什么,我们可以通过一些技术手段来完成这些信息的收集,从而在第一天开始收集数据。你不需要等自己的 API 有很多开发者之后才能开始进行数据的收集和反馈,只要设计合适的埋点,从 Day 1 就可以获取数据,并基于数据来分析指标和下一步优化的方案。
如何建设 TTFC/TTFHW
TTFC 和 TTFHW 的指标在实际的建设过程中并不容易。其中最大的问题是如何将开发者的行为和实际的调用进行关联。如果你的 API 在前端就可以发生调用,且能够在前端直接调用,还算是简单,可以通过简单的前端埋点来完成数据的建设,并配合开发者在网站上行为的埋点,来分析出具体的 TTFC / TTFHW。
而对于一些服务端的 API,则需要花费更多的心力来建立这些数据,你可能需要将开发者在网站上的行为和其对应的在 API 上的行为进行串联,从而形成一个完整的开发者图景。在最理想的情况下,你的统计系统和你的 API 网关系统上是可以打通的,你可以非常简单的将开发者在网站上的行为与发生在 API 网关系统上的行为进行串联,从而形成一整个从开发者进入网站到开发者了解 API 设计再到开发者真实发生 API 调用当中来完成。
不过,这件事在某些支持以应用身份来调用 API 的开放平台当中来说,就是比较困难的了。因为发生调用的最小单位是应用,而不是某一个人。但也并非绝对无解,你同样可以基于某些指标来圈选一部分开发者,并将这些开发者和实际网关当中产生调用的接口进行串联分析,得出开发者的实际的调用时长。
如何使用 TTFC / TTFHW
当你通过艰辛的数据埋点、数据收集、数据入仓之后,便可以进行数据分析,使用这些数据了。这里分享两个使用这些数据的思路,供你参考。
TTFC/TTFHW 的数据可以从整体数据视角和局部数据视角查看。
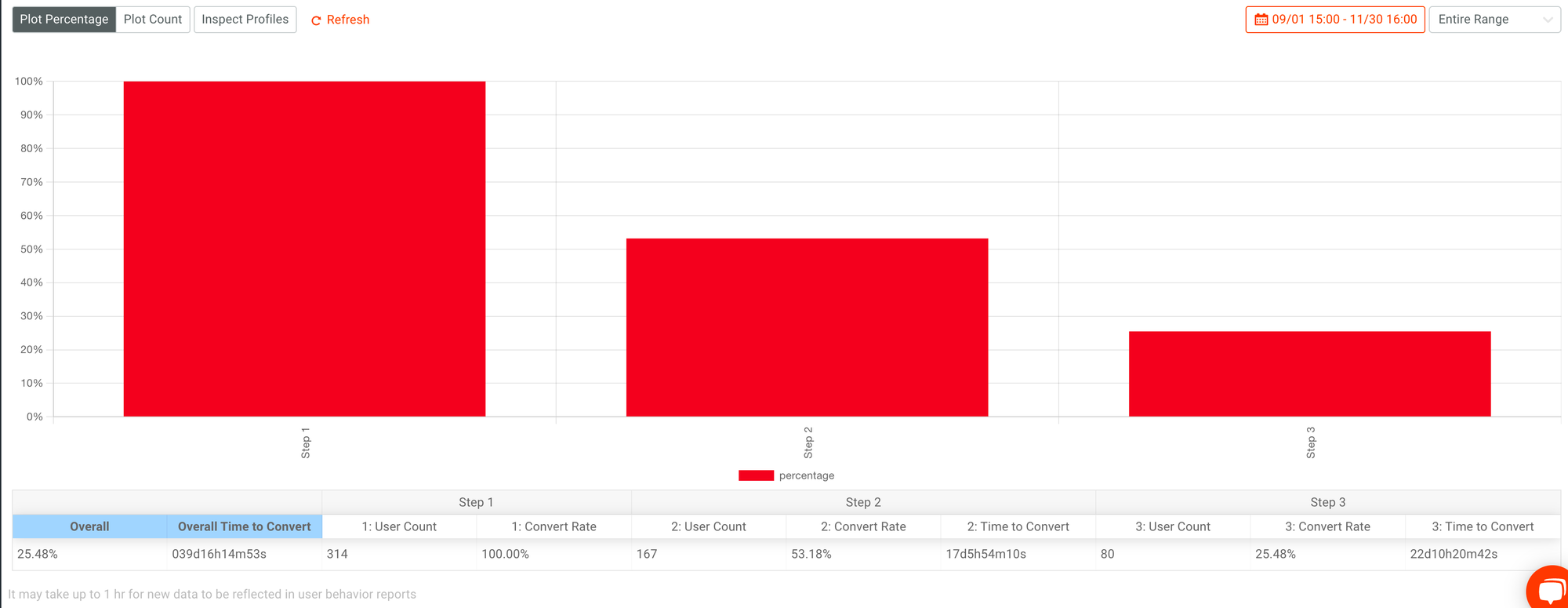
当你作为整体数据来查看时,你所拿到的是一个开发者完成整体调用所需的时长。你可以基于开发者的行为,来计算出开发者的 TTFC 所需的时长,和他进入到转化漏斗当中下一步所需的时间,并分析不同时长人群在实际转化率上的差异值,对比这些差异值,并得出判断和下一步的 Action ,优化你的 API 产品的实际体验,提升产品转化率。
当你作为局部数据来查看时,你可以将 TTFC/TTFHW 拆分成若干个不同的阶段,比如网站访问、查找文档、了解鉴权信息、阅读 API 文档、实际发生调用等多个阶段,并对这几个部分的耗时进行分析,从而得出一些定向优化的 Action ,来优化整个网站和 API 的质量,帮助开发者降低调用所需耗费的时长。
建设 TTFC / TTFHW 数据指标的一些建议
在建设 TTFC / TTFHW 的过程中,如果你遇到了困难,不妨试试如下的方式:
- 为你的服务端 API 提供一套在线的调试工具,从而让开发者可以在看文档的时候直接调用接口,测试效果。
- 如果你的 API 支持以开发者的身份调用,可以试着使用 OAuth 协议,让开发者在看文档的时候直接授权发起调用,并在调用成功之后给出相应的代码的生成。
一个可互动(Interactive)的文档,可以帮助你有效的降低 TTFC/TTFHW。
当然,除了产品本身的优化,你还可以试着提供更多的开发者教程、示例代码,来降低开发者调用你所提供的 API 的难度,优化开发者的体验。
关于 TTFC/TTFHW,你还有什么问题?欢迎你回信和我讨论。



